Key Lookups are Bad
Some background. We manage online reservations for a wide variery of customers. A key part of that is showing availability and rates. That is, for a given range of dates, which rooms are available? And, what rates are available for each day?
The core of our system for answering that question is a fairly straightforward stored procedure that calls into a few views and returns the necessary data to our application. It's fast already. I'm pretty happy with the performance to be honest.
In production, the database call takes 245ms. Locally, the same call takes 377 ms. If you want to know how long your sql takes to run, you can see that in SSMS (in the messages window) by running set statistics time on before running your query.
245ms in prod, 377ms local. Not bad. Let's make it faster.
I'm going to use Plan Explorer v1.3 by SQL Sentry. It's free and definitely worth installing. It shows a much nicer execution plan than SSMS and makes it so simple to correlate results that even a developer like me can do it.
Here's the problem area I'm going to focus on today:
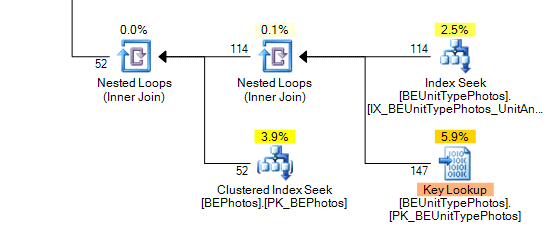

Let's talk a little bit about the table. It is, essentially, a join table between units and photos. It also has the sort order and some other meta data attributes on it.
For this, I only want the primary unit photo id, which is always sort order = 1.
A key lookup generally isn't a good thing. It means we're performing random I/O against our table to retreive data. In my specific case, I have an index, which is being used, for some initial filtering (unit id), but then I'm grabbing the primary key from that index (my photo id) and going back to the table (the key lookup) and grabbing the SortOrder column to finish the filter (select photoid where unitid = myunit and sortorder = 1).
We can rethink our index a bit in this case. In fact, a covering index would help. A lot. We can index based on unitid, photoid and sortorder.
Note: While the covering index helps here, it might not always. Measure, implement, measure again. Never assume.
The unit photo table could improve in another substantial way. This data is ultra high-read and ultra low-write. It's current clustered index is on an auto-incrementing integer primary key. This is pretty much a default pattern when most of us devs create a table (unless we're doing something awesome with guids). However, it's not always the best choice. In fact, my new covering index is a great, great candidate for being the clustered index on the table as well.
I'll make that change to my offending table(s) and then we'll verify that those key lookups are gone:

Local execution time is down from 377ms to 250ms. While this doesn't seem like a huge improvement, I have less data locally than production. And, every little bit helps. The quicker we can answer our users, the better. I can't wait to get this to prod!